

How We Secure our Tier Zero Service
Shoreline.io, like any observability tool, any incident management tool, or any incident automation tool, is a tier zero service. Tier zero services need to stand up - even when other things are burning down.
Learn from our quick explanations, demos, and best practices.
Shoreline.io, like any observability tool, any incident management tool, or any incident automation tool, is a tier zero service. Tier zero services need to stand up - even when other things are burning down.

Observability tools rank as the 3rd-highest cost for engineering teams after their people and cloud infrastructure. That’s insane! What's even more insane? You hardly ever use the collected data.

How can we establish powerful production operations that avoid allowing SREs unrestricted SSH access to production environments? Here are four measures we implement to safeguard services.

Razorpay, a FinTech leader in India, built ARCTIC, a security & response solution coupling pinpoint accuracy in threat detection with rapid remediation from Shoreline. They posted a recent video about how they did it.

Because it's less expensive and quicker for passengers, Southwest operates on a point-to-point model. Any disruptions in one route affect the entire chain. But to engineer a reliable architecture, you need to balance cost versus reliability in an economically constrained way.

The bigger the data set, the slower it is to analyze. For MELT, you need to be able to execute a query at scale across your fleet and see what's going on in the live environment. That’s why, at Shoreline, we favor modeling the distributed system as a distributed system.

In any company, 50-80% of the alarms are noisy. Employees get trained to snooze these alarms – which isn’t always the right thing to do. Wouldn't it be better if you could easily see which are your top issues each week, and which alarms might be set incorrectly?

I deeply believe in making things 1% better each and every week by improving the performance of the software I've been responsible for and keeping my services up. Let’s talk about bringing continuous improvement to operations.

It's not some other team's job to keep your service up. Just like it's not some other team's job to fix your bugs or make sure that your system doesn't have vulnerabilities. We all have to own it. That is what a culture of reliability requires.
Availability for the 4 nines is equivalent to only 4.4 minutes of downtime in a month. Here are 3 challenges that keep people from meeting customer expectations for service availability.

A ton of tools help you observe your environment and maybe half a ton help you route things and deduplicate them. But there's hardly anything out there that actually fixes your environment. That's the reason we need automation in production ops today.

Learn step by step how to setup Shoreline's Incident Insights so that you can pinpoint the top causes of incidents, measure team health, and use trending data to drive continuous improvement. Get up and running in 2 minutes.

Since we’re all sitting on similar infrastructure, if someone solves an issue, everyone should be able to benefit from it. That’s one of the ways we help our customers to save time, reduce errors, and get to a four 9’s SLA.

I know I should apply continuous improvement to operations. But where do I start? See how our free Incident Insights tool helps you remove noise and increase signal, making your team more productive and reducing costs by decreasing toil.

Amazon S3's 11 nines claim promises near-immortal data storage, but real-world factors like solar events and correlated failures challenge this durability. Understanding the limits is crucial for robust system design.

What can we learn from the Ticketmaster (Taylor Swift) Debacle? Ticketmaster experienced an unprecedented demand that resulted in their site crashing for many hours. If they had designed a reliable service with an escalator-like system instead of an elevator, this could have been avoided.

Hear from Shoreline Op Pack Engineer, Kaustubh Prabhakar, on how valuable it is to use our Idle EC2 Cost Savings Op Pack.

Prioritize automating frequent issues for efficiency. Automate critical tasks for safety and error reduction. AWS strategy: automate one issue weekly for significant yearly impact. Shoreline simplifies automation, aiming for quick, lasting fixes, transforming work efficiency.

Hear from Shoreline Op Pack Engineer, Kaustubh Prabhakar, on how valuable it is to use Shoreline Unauthorized Root Access Detector.

Charles Carey, Shoreline's Chief Technology Officer, walks us through Shoreline's automation runbook experience.

Obsessing about customers is important, but so is creating a culture where people take care of others and feel cared for. That’s why we put our values right on our website.

Part of the reason to create a company is to create the environment you want to be in.So it’s important that you reflect your values in your interview process. Otherwise, the sheer number of people joining will dilute things.

Automation is risky. Errors in the remediation code could worsen an outage. While that’s true, we also know that human error causes 5x more incidents than automation. You can fix code. You can't fix people.

Some issues can't be automated. For things that require human judgment, we provide on-call teams with notebooks that are optimized for operations. That way you know what action to take and when.

Automation takes us too much time. We're way too busy fighting fires to think about it. The problem with this approach is that 48% of incidents are straightforward and repetitive. Don't have people fix them manually. Teach the computer how to do it.

Anurag Gupta joined John Walls to discuss innovation in the cloud with DevOps teams for the Global Startup Program at AWS re:Invent 2022.

Hear how TigerGraph VP of Product and Innovation, Dr. Jay Yu, used Shoreline to drive continuous improvement and bring up the productivity of his DevOps teams.
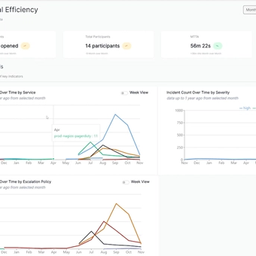
Shoreline's Incident Insights turns messy incident data into insights for FREE

Hear from Senior Director, Haritha Gongalore, on how rewarding it is to use Shoreline Alarms and Actions to test and certify our own releases.
![[Training] Debugging Kubernetes with Runbooks](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2F5a5th78w%2Fproduction%2F06b45a24fcf978b5949a9bf918b187f5e106944e-1194x671.png%3Frect%3D262%2C0%2C671%2C671%26w%3D256%26h%3D256%26fit%3Dmax%26auto%3Dformat&w=3840&q=100)
In this training, we walk you through the common issues and challenges troubleshooting Kubernetes, and Shoreline's pre-built K8s debugging runbooks.

Ashley Stirrup dives into the hidden costs of on-call and discuss how one team saved 20 hours of DevOps time per month thanks to Shoreline.io automations.

How can you better utilize the resources you keep aside for failover purposes? Here's how we utilized resources kept just for failover purposes to do things that could be stopped for some time when a failure happens and had resources doing useful background activity that can be deferred to when things hit the fan.

Shoreline's back ends are low utilization most of the time. But once an hour, we pull telemetry data from all agents, resulting in a CPU, memory, and network utilization spike. See how we convert over-provisioned resources for demand spikes to waste and eliminate it.

Waste is when resources are deeply over-provisioned, underutilized, or not utilized at all. Slack appears like the same thing, but you create it with purpose. It's important to understand the difference to drive costs down.

Most of the on-call issues are commonplace, which means they happen again and again. It’s important to automate these issues because it’s a one-time investment, doesn’t make mistakes, and stays with you forever.

Automating mundane tasks and debugging were just a few of the DevOps requirements TigerGraph VP of Product and Innovation, Dr. Jay Yu, needed to scale in the cloud with his small team. Shoreline delivered.

Automaton Anywhere links Sumo Logic's data and log monitoring with Shoreline's automated incident repairs to improve customer experiences and save Dev time

It’s not a presentation – you don’t tell people what to do. You simply put the facts on the table in a neutral tone.

We're all being asked to do more with less now a days. For those of us in production operations, one of the best ways we can do that is eliminate waste with automation to drive higher utilization.
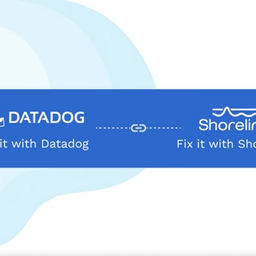
Find it with Datadog. Fix it with Shoreline.

If your on-call sucks, you must find a path to make incidents incidental.

Op Packs available for free with Shoreline.

Debug across the fleet in about the same amount of time as an individual box.

Improve your on-call by building automations that eliminate common production incidents.

Continuous improvement in operations is possible by automating few IT incident tickets on a regular basis

1. Reduce waste, 2. Optimize what you’re using, and 3. Move towards reserved instances (RIs)

All we could do was apply automation to fix the issues when they occurred, providing customers much better availability.
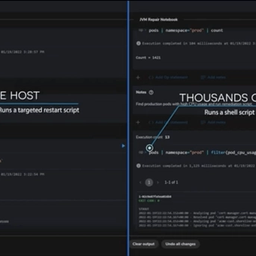
Safely fix incidents across your entire fleet, with less overhead, and with fewer errors.
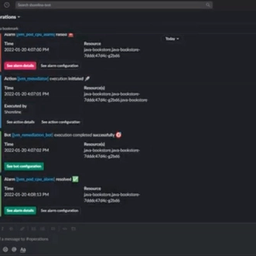
Easily and safely automate incident remediations with a few lines of code.

It requires predictive maintenance, including monitoring brownout and performing control actions

It's critical to close ports that can be opened unintentionally in a development environment, especially port 22 for SSH and port 3389 for remote login.
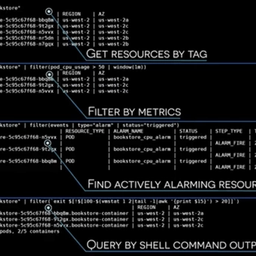
Run a single command across the entire fleet to diagnose incidents more quickly.

Underneath the covers, the underpinning technology is a lot like a parallel SQL database.

See issues and act in real-time, directly from Datadog
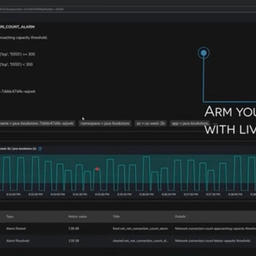
Record, curate, and publish incident debug and repair best practices to safely empower on-call teams.
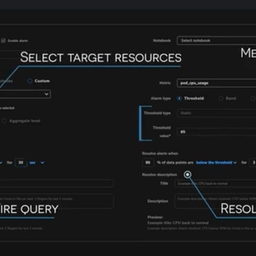
Shoreline Alarms identify issues with high specificity so that they are immediately actionable.

Incident automation helps people automatically fix issues in production, and grow the number of people who can safely fix things without escalation.
Shoreline makes it easy to collect diagnostic information when you're doing a root-cause analysis of an issue.
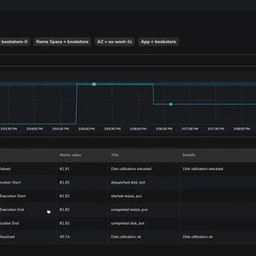
See Shoreline in action, debugging an incident and automating remediations in a fraction of the usual time.

Wavelets are the best way to deal with errors in the underlying data stream

Often people try to build a solution like Shoreline on their own. Here's why they fail.

Discover how to manage operational data for debugging and trend analysis efficiently, reducing costs and enhancing real-time insights with Shoreline.io's innovative approach.

How can companies increase reliability without hiring an army of engineers?

Companies spend more on the people managing their cloud infrastructure than on the cloud infrastructure itself.

Shoreline helps on-call operators reduce incidents resulting in a better on-call experience and better availability for their customers.

Niall Murphy, former SRE at Google and Microsoft and author of the O'Reilly book, Site Reliability Engineering, shares his experience of using Shoreline's Incident Automation Platform.
Shoreline’s Incident Automation Platform was built to reduce manual and repetitive work, so that you can repair issues faster, increase team productivity, and eliminate thousands of hours of degraded service.