

The CLI allows you to issue Op commands across your fleet. Op is an operations-oriented language that helps you diagnose, debug, resolve, and automate remediation. These commands target Resources, which are your core infrastructure objects such as hosts, pods, and containers.
The first step to debugging with Shoreline is discovering Resources. The demo starts by using a simple
command, which finds all hosts with the Shoreline Agent installed. Shoreline supports a variety of platforms and installation techniques.
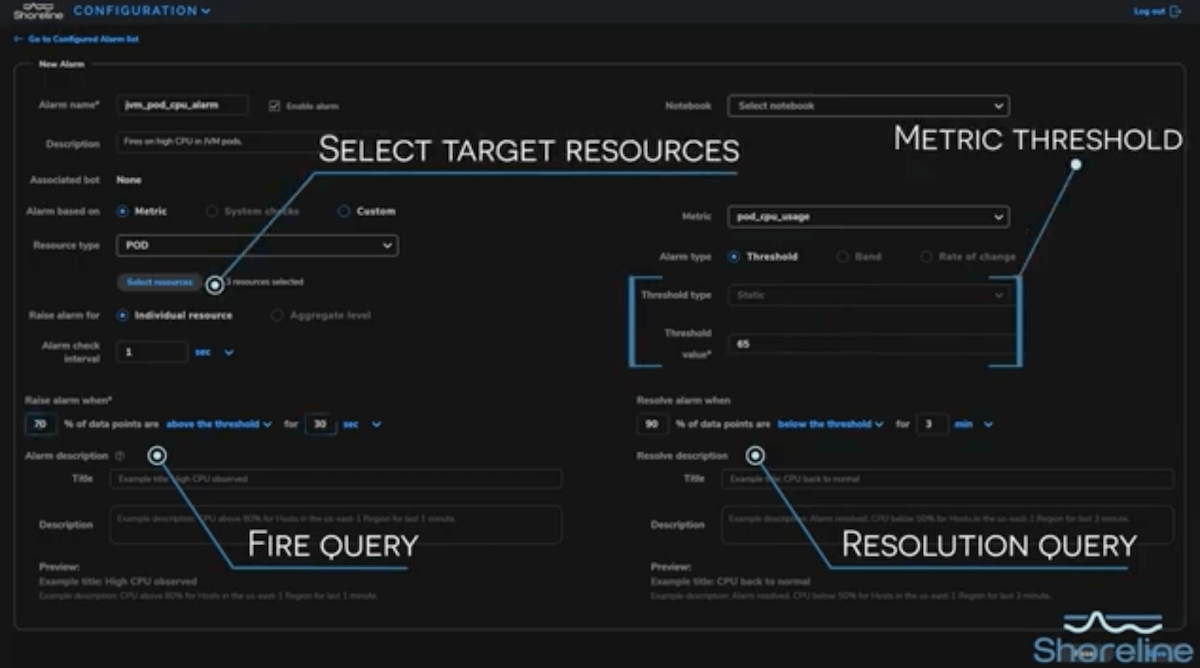
From there, we're using basic Resource filtering to select a collection of containers with a shoreline app. However, there are many more advanced ways to filter, including via regex, Metric queries, Linux commands, and more.
In the next step, we evaluate the Resources using one of the hundreds of standard Metrics available in Shoreline, based on the Prometheus node exporter. In this case, we're evaluating the current CPU usage of our containers. In the demo scenario, one of our containers is experiencing excessive CPU load and a process must be terminated.
The final step is to resolve this issue by using a dynamic, Metric-based filter to identify which (unknown) container is problematic:
From there, we pipe a custom Linux command to execute against those targeted Resources, which kills the troublesome process:
That last command combines a lot of the power of Shoreline into a single line. We're able to combine the results of smaller statements into a powerful Op command:
- Gets a basic collection of Resources
- Refines the Resources to only those experiencing issues
- Executes a Linux command to resolve the issue
As you can see, Shoreline empowers you and your team by vigilantly monitoring every object within your fleet in real-time. First, query and filter your resources using hundreds of standard metrics, making it easy to identify potential problems. Then, execute unrestricted Linux commands against the target resources to immediately resolve the issue.
Stay tuned for a future video where you'll learn how to automate this entire process with Alarms, Actions, and Bots!