

Managing Zombie Processes in Containers
In container environments, the main process manages child processes. Poor management can lead to orphan processes, draining resources and risking operational integrity.
Read the latest stuff we're up to and what we're most excited about.
In container environments, the main process manages child processes. Poor management can lead to orphan processes, draining resources and risking operational integrity.

In this candid insight, Anurag shares valuable lessons on utilizing queues in system design for enhanced reliability, learned from firsthand experiences at AWS.

Throughout 2023 Shoreline’s founder and CEO, Angug Gupta, shared his thoughts on DevOps and cloud operations excellence in many short videos on our YouTube channel. We’ve selected the five insights that stood out for DevOps and Cloud teams looking to innovate tools and processes in 2024.

Delve into our blog about the intricacies of on-call operations, drawing from Shoreline's 2022 survey insights. Over 300 experts discuss the high costs and challenges faced, with tips for reducing escalations and automating tasks. Discover how Shoreline's tools can revolutionize your on-call strategy.

Constellation Research's 2023 IT Ops report shows incident resolution costs $20-100M annually for big firms, highlighting automation's necessity in modern digital incident management.

Shoreline recently helped Razorpay, a FinTech leader in India, elevate their system reliability and improve developer productivity by 25% as part of their strategic initiative for incident automation.

Shoreline.io, like any observability tool, any incident management tool, or any incident automation tool, is a tier zero service. Tier zero services need to stand up - even when other things are burning down.

Observability tools rank as the 3rd-highest cost for engineering teams after their people and cloud infrastructure. That’s insane! What's even more insane? You hardly ever use the collected data.
In this RedMonk Conversation, Stephen O'Grady and Anurag Gupta discuss how generative AI can help address reliability challenges and incident response.

How can we establish powerful production operations that avoid allowing SREs unrestricted SSH access to production environments? Here are four measures we implement to safeguard services.

Razorpay, a FinTech leader in India, built ARCTIC, a security & response solution coupling pinpoint accuracy in threat detection with rapid remediation from Shoreline. They posted a recent video about how they did it.

DASH, by Datadog, is an annual conference with two days packed with hands-on learning and inspiration. Let’s build and scale the next generation of applications, infrastructure, security, and technical teams together.

Join Shoreline.io at Monitorama and Observa-Palooza to share reliability best practices and have some fun.

Observability in software ops is key for proactive issue resolution, going beyond data collection to include decisive actions based on logs, metrics, and traces. Not acting on insights leads to reduced productivity and poor user experiences.

Because it's less expensive and quicker for passengers, Southwest operates on a point-to-point model. Any disruptions in one route affect the entire chain. But to engineer a reliable architecture, you need to balance cost versus reliability in an economically constrained way.

The bigger the data set, the slower it is to analyze. For MELT, you need to be able to execute a query at scale across your fleet and see what's going on in the live environment. That’s why, at Shoreline, we favor modeling the distributed system as a distributed system.

In any company, 50-80% of the alarms are noisy. Employees get trained to snooze these alarms – which isn’t always the right thing to do. Wouldn't it be better if you could easily see which are your top issues each week, and which alarms might be set incorrectly?

I deeply believe in making things 1% better each and every week by improving the performance of the software I've been responsible for and keeping my services up. Let’s talk about bringing continuous improvement to operations.

It's not some other team's job to keep your service up. Just like it's not some other team's job to fix your bugs or make sure that your system doesn't have vulnerabilities. We all have to own it. That is what a culture of reliability requires.
Availability for the 4 nines is equivalent to only 4.4 minutes of downtime in a month. Here are 3 challenges that keep people from meeting customer expectations for service availability.

A ton of tools help you observe your environment and maybe half a ton help you route things and deduplicate them. But there's hardly anything out there that actually fixes your environment. That's the reason we need automation in production ops today.

Learn step by step how to setup Shoreline's Incident Insights so that you can pinpoint the top causes of incidents, measure team health, and use trending data to drive continuous improvement. Get up and running in 2 minutes.

Since we’re all sitting on similar infrastructure, if someone solves an issue, everyone should be able to benefit from it. That’s one of the ways we help our customers to save time, reduce errors, and get to a four 9’s SLA.

I know I should apply continuous improvement to operations. But where do I start? See how our free Incident Insights tool helps you remove noise and increase signal, making your team more productive and reducing costs by decreasing toil.

Amazon S3's 11 nines claim promises near-immortal data storage, but real-world factors like solar events and correlated failures challenge this durability. Understanding the limits is crucial for robust system design.

Shoreline founder and CEO, Anurag Gupta, joins Stephen Townshend to discuss the value of community, collaboration between organizations, vicious versus virtuous cycles for reliability, and more.

Shoreline founder and CEO, Anurag Gupta, joins Barry O’Reilly to share the importance of embracing failure, creating a blameless culture, and his first-hand knowledge on how to build more reliable and resilient systems.
Shoreline founder and CEO, Anurag Gupta, joins Niall Murphy, Co-founder & CEO of Stanza, and Stephen Townshend, Host of the Slight Reliability Podcast, to discuss the importance of investing in reliability and the new reliability.org community.

Anurag Gupta joins Corey Quinn to discuss the large variety of services he helped launch and his transition back to start-ups with the founding of Shoreline.

What can we learn from the Ticketmaster (Taylor Swift) Debacle? Ticketmaster experienced an unprecedented demand that resulted in their site crashing for many hours. If they had designed a reliable service with an escalator-like system instead of an elevator, this could have been avoided.

Hear from Shoreline Op Pack Engineer, Kaustubh Prabhakar, on how valuable it is to use our Idle EC2 Cost Savings Op Pack.

Learn the best practices when building an effective SRE job description, including some sample copy, to help SRE leaders improve how they recruit team members.

Twitter’s recent outage highlights the dangers of errors and staff shortages. Safeguard your business by implementing automated reliability solutions.

Every year, we look forward to connecting with our local DevOps community at SLC DevOps Days; Sharing and learning from experts in our community, and working with DevOps thought leaders that visit our event. We are very excited to be back in Salt Lake City March 14-15, 2023.

The Cloud Native Computing Foundation’s flagship conference gathers adopters and technologists from leading open source and cloud native communities in Chicago, Illinois from November 6-9, 2023.

Join us in person for AWS Summit New York to see how your peers and competitors are using the cloud to their advantage and learn all the ways you can use AWS to jump-start, grow, or supercharge your business and career to the next level. AWS Summit New York is a free event.

Monitorama brings together the brightest minds among the open source development and operations communities to continue to push the boundaries of observability software and practices, all while having a great time in a casual setting. Join us in Portland, Oregon June 26-28, 2023.

We asked the Shoreline team what predictions they have for cloud reliability in 2023. Here’s what we learned about cloud adoption, automation, and more.
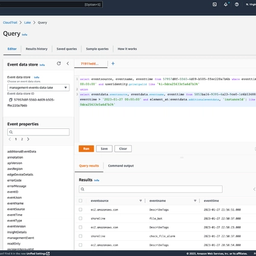
Shoreline's partnership with AWS CloudTrail Lake enables Shoreline and AWS customers to use CloudTrail Lake as their single source of truth for auditing events.
In a compelling discussion, Evan and Anurag delve into the intricacies of Shoreline's AI Ops platform for incident response. Anurag, drawing from his experience leading reliable services at AWS, highlights the challenges of maintaining high availability in the face of rapid growth. He emphasizes the role of innovative automations in ensuring consistent service for demanding customers. Anurag suggests the first step in driving reliability for cloud services is understanding the root causes of incidents. He points to Shoreline's free tool designed to aid in this process. The conversation also features a case study of a major Shoreline client managing a 30,000-node fleet across multiple clouds and regions. Anurag shares how the client efficiently handles security checks and issue detections over thousands of instances simultaneously, treating the entire fleet as a single entity. For a deeper dive into this insightful discussion, the full video podcast is available on YouTube and LinkedIn.
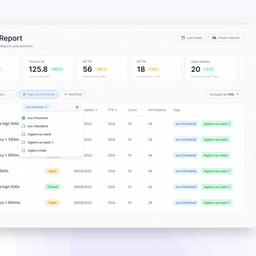
We get it, incident data is difficult to read. Dive into three different and effective ways to categorize and filter your data to gain actionable insights.

Prioritize automating frequent issues for efficiency. Automate critical tasks for safety and error reduction. AWS strategy: automate one issue weekly for significant yearly impact. Shoreline simplifies automation, aiming for quick, lasting fixes, transforming work efficiency.

Hear from Shoreline Op Pack Engineer, Kaustubh Prabhakar, on how valuable it is to use Shoreline Unauthorized Root Access Detector.

Charles Carey, Shoreline's Chief Technology Officer, walks us through Shoreline's automation runbook experience.
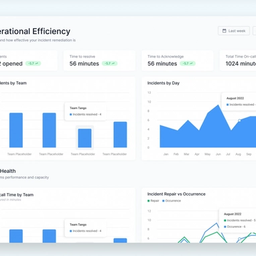
Ticketing data is messy. This new, free tool allows leaders to contextualize data to understand what issues occur most frequently and how long they take to resolve.

Obsessing about customers is important, but so is creating a culture where people take care of others and feel cared for. That’s why we put our values right on our website.

Part of the reason to create a company is to create the environment you want to be in.So it’s important that you reflect your values in your interview process. Otherwise, the sheer number of people joining will dilute things.

Automation is risky. Errors in the remediation code could worsen an outage. While that’s true, we also know that human error causes 5x more incidents than automation. You can fix code. You can't fix people.

Some issues can't be automated. For things that require human judgment, we provide on-call teams with notebooks that are optimized for operations. That way you know what action to take and when.

Automation takes us too much time. We're way too busy fighting fires to think about it. The problem with this approach is that 48% of incidents are straightforward and repetitive. Don't have people fix them manually. Teach the computer how to do it.
During AWS re:Invent 2022, Shoreline Software announced its Incident Insights solution, a free, AI-powered tool intended to help CloudOps teams analyze their incidents.

Anurag Gupta joined John Walls to discuss innovation in the cloud with DevOps teams for the Global Startup Program at AWS re:Invent 2022.

Hear how TigerGraph VP of Product and Innovation, Dr. Jay Yu, used Shoreline to drive continuous improvement and bring up the productivity of his DevOps teams.
AI-powered tool automates the categorization, filtering, and analysis of incidents.

The biggest takeaways and trends from Google Cloud and DORA’s 2022 State of DevOps report.
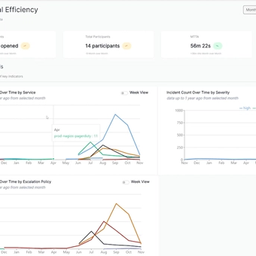
Shoreline's Incident Insights turns messy incident data into insights for FREE

To ensure success within your on-call operations, you’ll need to understand what causes escalation, how it affects on-call teams, and how to reduce them.

Hear from Senior Director, Haritha Gongalore, on how rewarding it is to use Shoreline Alarms and Actions to test and certify our own releases.
![[Training] Debugging Kubernetes with Runbooks](/_next/image?url=https%3A%2F%2Fcdn.sanity.io%2Fimages%2F5a5th78w%2Fproduction%2F06b45a24fcf978b5949a9bf918b187f5e106944e-1194x671.png%3Frect%3D262%2C0%2C671%2C671%26w%3D256%26h%3D256%26fit%3Dmax%26auto%3Dformat&w=3840&q=100)
In this training, we walk you through the common issues and challenges troubleshooting Kubernetes, and Shoreline's pre-built K8s debugging runbooks.

Shoreline helps TigerGraph scale in the cloud with a small operations team by automating mundane tasks and quickly finding the root cause of degraded service.
Diagnose and Repair Kubernetes Issues Across Pods, Nodes, and Services in Minutes

Ashley Stirrup dives into the hidden costs of on-call and discuss how one team saved 20 hours of DevOps time per month thanks to Shoreline.io automations.

At Sumo Logic’s Illuminate conference, Automation Anywhere discussed how the company optimizes production operations with Shoreline’s cloud reliability platform.
With a more productive and future-focused team, you can proactively eliminate the root causes that lead to major incidents and create tools that shorten time to resolution.
Improve customer satisfaction and reduce toil with instant fixes to common production incidents.

How can you better utilize the resources you keep aside for failover purposes? Here's how we utilized resources kept just for failover purposes to do things that could be stopped for some time when a failure happens and had resources doing useful background activity that can be deferred to when things hit the fan.

Shoreline's back ends are low utilization most of the time. But once an hour, we pull telemetry data from all agents, resulting in a CPU, memory, and network utilization spike. See how we convert over-provisioned resources for demand spikes to waste and eliminate it.

Waste is when resources are deeply over-provisioned, underutilized, or not utilized at all. Slack appears like the same thing, but you create it with purpose. It's important to understand the difference to drive costs down.

Most of the on-call issues are commonplace, which means they happen again and again. It’s important to automate these issues because it’s a one-time investment, doesn’t make mistakes, and stays with you forever.

Automating mundane tasks and debugging were just a few of the DevOps requirements TigerGraph VP of Product and Innovation, Dr. Jay Yu, needed to scale in the cloud with his small team. Shoreline delivered.
Automaton Anywhere links Sumo Logic's data and log monitoring with Shoreline's automated incident repairs to improve customer experiences and save Dev time

It’s not a presentation – you don’t tell people what to do. You simply put the facts on the table in a neutral tone.

We're all being asked to do more with less now a days. For those of us in production operations, one of the best ways we can do that is eliminate waste with automation to drive higher utilization.
Find it with Datadog. Fix it with Shoreline.

If your on-call sucks, you must find a path to make incidents incidental.

Downtime and site reliability issues happen far too often. Operations teams need to focus on these three productivity hacks so teams can tackle more with less.

Op Packs available for free with Shoreline.

Debug across the fleet in about the same amount of time as an individual box.

Improve your on-call by building automations that eliminate common production incidents.

Shoreline founder and CEO, Anurag Gupta, joins Dr. Jay Yu, TigerGraph's VP of Product and Innovation, to discuss innovative ways to scale cloud operations fast without the need to incur a lot of costs and keep expanding the cloud DevOps team in this webinar hosted by DevOps.com.

Anurag Gupta and Ashley Stirrup presented data and insights from a survey conducted with 300 on-call practitioners, managers and executives at this DevOps.com hosted webinar on Sept 7th, 2022.

DevOps is complicated. Incident automation is a new function within DevOps that enables engineers to optimize performance, reduce toil, and improve innovation.

Our 2022 Benchmarking Production Operations Report reveals the leading cause of major incidents, and the impact of escalation, toil, and more.
The main challenge in preventing outages lies in the inevitable breakdown of various components like disks, nodes, and networks. To mitigate this, companies need to acknowledge human error as an unavoidable factor, especially when numerous commands are manually inputted daily. Investigating how minor errors can cause significant damage and implementing safeguards and redundancies are essential steps to reduce the risks and impacts of potential outages.
On Average, Companies Spend 12 Person Years On Incident Response Annually

Shoreline announces customer-driven enhancements that provide enterprise customers with critical safeguards against human errors when executing large scale automations across their multi-cloud infrastructure.

Continuous improvement in operations is possible by automating few IT incident tickets on a regular basis

Here are three tips for automatically fixing the most common Kubernetes issues through mastering Kubernetes, self-healing, and staying proactive.
Shoreline’s library of pre-built Op Packs offers open source solutions for common production operations incidents, eliminating operational toil and increasing availability
The biggest opportunity to improve on-call productivity is by reducing incident escalations, which account for 78% of on-call time, according to a new report from Dimensional Research and Shoreline.io.
Shoreline's pre-built op packs are geared at addressing common production operations incidents to increase teams’ productivity.

Almost 170 remediations were automatically triggered last month, conservatively saving over 20 FTE days of DevOps work, while improving app performance.

1. Reduce waste, 2. Optimize what you’re using, and 3. Move towards reserved instances (RIs)

Peter Bell from CTO connection chatted with Anurag about the importance of automating production ops.

All we could do was apply automation to fix the issues when they occurred, providing customers much better availability.
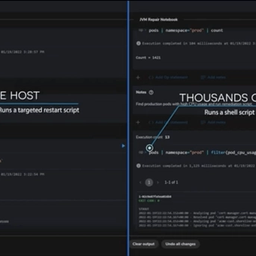
Safely fix incidents across your entire fleet, with less overhead, and with fewer errors.
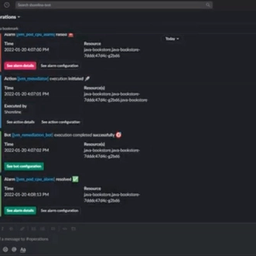
Easily and safely automate incident remediations with a few lines of code.

It requires predictive maintenance, including monitoring brownout and performing control actions

It's critical to close ports that can be opened unintentionally in a development environment, especially port 22 for SSH and port 3389 for remote login.
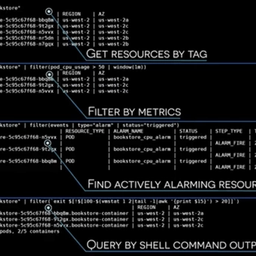
Run a single command across the entire fleet to diagnose incidents more quickly.

Underneath the covers, the underpinning technology is a lot like a parallel SQL database.

See issues and act in real-time, directly from Datadog
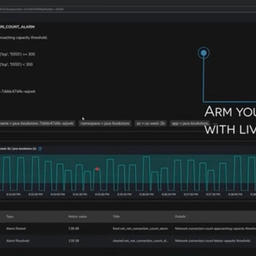
Record, curate, and publish incident debug and repair best practices to safely empower on-call teams.
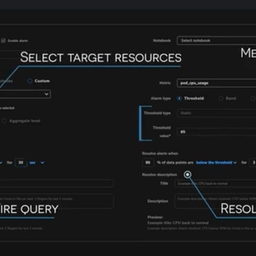
Shoreline Alarms identify issues with high specificity so that they are immediately actionable.

Dash, by Datadog, is an annual conference about building and scaling the next generation of applications, infrastructure, security, and technical teams, hosted in 2022 at Javits Center North, New York.

Incident automation helps people automatically fix issues in production, and grow the number of people who can safely fix things without escalation.
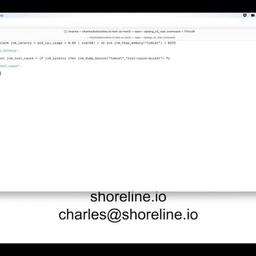
Shoreline makes it easy to collect diagnostic information when you're doing a root-cause analysis of an issue.
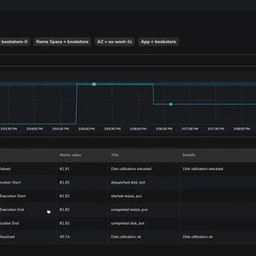
See Shoreline in action, debugging an incident and automating remediations in a fraction of the usual time.

Anurag had the opportunity to chat with Jeff Myerson on his podcast, Software Engineering Daily

The Cloud Native Computing Foundation’s flagship conference gathers adopters and technologists from leading open source and cloud native communities in Detroit, Michigan from October 24 – 28, 2022.

For 10 years, the global cloud community has come together at re:Invent to meet, get inspired, and rethink what's possible. Join us again this year in Las Vegas for our biggest, most comprehensive, and most vibrant event in cloud computing.

Wavelets are the best way to deal with errors in the underlying data stream
An Interview With Fotis Georgiadis - Overcoming the struggle in taking a good idea and translating it into an actual business.

Often people try to build a solution like Shoreline on their own. Here's why they fail.

Discover how to manage operational data for debugging and trend analysis efficiently, reducing costs and enhancing real-time insights with Shoreline.io's innovative approach.

How can companies increase reliability without hiring an army of engineers?

Companies spend more on the people managing their cloud infrastructure than on the cloud infrastructure itself.

Shoreline helps on-call operators reduce incidents resulting in a better on-call experience and better availability for their customers.

Niall Murphy, former SRE at Google and Microsoft and author of the O'Reilly book, Site Reliability Engineering, shares his experience of using Shoreline's Incident Automation Platform.
Shoreline’s Incident Automation Platform was built to reduce manual and repetitive work, so that you can repair issues faster, increase team productivity, and eliminate thousands of hours of degraded service.

Redmonk Analyst and Steve O'Grady sits down with Anurag Gupta to define automated remediation

In this webinar, John Egan, CEO of Kintaba, and Anurag Gupta, CEO of Shoreline, discuss the role humans and machines play when dealing with failures and responding to disasters.

InfoQ webinar: 5 Technical Lessons Learned from Outages at AWS, Google and Microsoft

In this podcast Anurag Gupta, founder and CEO of Shoreline.io, sat down with InfoQ podcast host Daniel Bryant and discussed: the role of DevOps and site reliability engineering (SRE), day 2 operations, and the importance of building observability into applications and platforms.

Get actionable strategies for reducing toil so your SRE and DevOps teams can spend more time on projects that create net-new value for your business.

Processing, analyzing, then acting on observability data entirely within your own environment offers a cheaper, faster, fault tolerant, and more secure alternative.
The Shoreline Datadog App enables users to leverage Shoreline's debug and repair features entirely within the Datadog UI.
Rethink on-call with automation to tackle repetitive incidents, reduce errors, and free up time for innovation in complex production fleets.
The Incident Automation company Shoreline.io announced a collection of Op Packs that make it easier to diagnose and repair common infrastructure incidents in production cloud environments called the Shoreline open source solutions library.

Streamline IT ops with runbooks to efficiently solve routine problems, paving the way for automation and freeing SMEs for higher-value tasks.
With $35M in new funding, Shoreline is addressing "missing piece" to automate incident response for production operations.
New funding allows company to expand its mission to help customers improve availability, reduce toil, and free up time for engineers to build

New funding allows company to expand its mission to help customers improve availability, reduce toil, and free up time for engineers to build

Learn how to manually and automatically resize a disk, including error handling

Curious about site reliability engineering (SRE) and how it can help you iron out incidents more efficiently and consistently? Read this guide to learn more.

Runbook automation can transform your operations; eliminating repetitive tasks and late-night calls, and enhancing team efficiency and system reliability. Find out more about what this process is, and how it can be implemented with your team.
The biggest CloudOps challenge is often just keeping things running as expected.
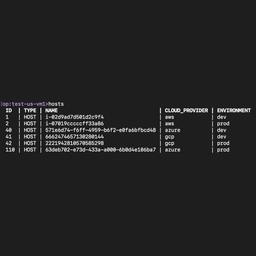
Shoreline’s platform hides complexity, eliminates the pain, and makes multi-cloud operations easy on the team.
Added support for GCP and Azure enables Shoreline customers to debug, repair, and automate across multi-cloud environments, reducing operations complexity
Shoreline.io was named one among top 15 promising startups that Database Trends and Applications is watching in 2022.
Learn from tech giants like Apple & Google: their strategic choices and a culture accepting failures fuel innovation and success.
With Shoreline.io platform now available on AWS, Azure and Google Cloud, site reliability engineers have the ability to significantly improving the availability of cloud hosted applications and services.
Shoreline COO Ashley Stirrup shares his predictions for 2022.
Ashley Stirrup, COO at Shoreline.io shares his 2022 predictions about the death of the Runbook, the rising cost of outages and SRE hiring trends.
Online Notebooks can be tied to alarms, making it easier to resolve incidents.
Unlike runbooks, Shoreline Notebooks real-time debug data and dynamic repair actions enable everyone on-call to be as good as their best SRE

Using Shoreline's Oplang and Metrics System to Solve Advent of Code Puzzles
Experienced Marketing Leader Joins Hyper-Growth Incident Automation Company to Scale Go-To-Market Efforts
Ensure engineering best practices including code reviews, test pipelines, and version control.
Explore the balance between centralized and decentralized ops, and how simple oversights can lead to major outages and urgent fixes.
Datadog’s cloud monitoring together with Shoreline’s incident automation provides customers with closed-loop incident detection, diagnosis, and repair
Organizations need to have the right technical and cultural atmosphere in place to reduce the risk, duration, and impact of outages.
Handle remediation with the same Terraform workflow you use to provision and manage infrastructure.

Important lessons and valuable experiences while developing Shoreline's Azure Agent.
Incident Automation Company Expands Executive Team to Drive Next Phase of Growth

DevOps leaders can apply infrastructure as code lessons and tooling to production ops, use solutions like Terraform + Shoreline to automate repeatable tasks, and make hero-level institutional knowledge accessible to anyone.
Unlock the power of automation for fleet-wide remediation. Learn how Alarms, Actions, Bots, and Resources streamline your infrastructure management, all accessible through an intuitive CLI.
Jupyter Notebooks for DevOps

Learn how to resolve Kubernetes DNS issues with Shoreline's CoreDNS Op Pack.

For our Intern Spotlight series, we’ll showcase the work of a summer intern at Shoreline with a technical deep dive.

Shoreline’s Argo Op Pack is purpose-built to remediate IP exhaustion related to Argo workflows automatically.

Execute 1,000s of alarms on box, with 1 second of delay.
Observability in software ops is key for proactive issue resolution, going beyond data collection to include decisive actions based on logs, metrics, and traces. Not acting on insights leads to reduced productivity and poor user experiences.
Fix once, automate the solution, and then deploy many times.
Company Launches New Platform Designed to Automatically Fix Common Issues that Arise in Operating Systems and to Interactively Debug Issues in Real-time, Across Fleets

Reduce on-call fatigue with Shoreline.io's automation, transforming production ops from manual toil to efficient, real-time issue resolution.

Shoreline’s metrics team has machine learning technologies from Google, JAX and XLA, to accelerate metric query and data analysis so SREs can run ad hoc queries in real-time.
An interview with Paul Moss - The intuition of when to persevere and when to pivot is the mark of a great founder.

Explore the evolution of DevOps automation, from deployment to operational efficiency, enhancing reliability and reducing manual toil.
Discover Anurag Gupta's journey of reinvention in 'Second Chapters', revealing the pivotal moments and qualities that shaped his path.
Shoreline.io boosts incident automation with new advisory members, aiming for higher uptime and reduced operator toil through cutting-edge automation.
Shoreline.io joins Intellyx 2021 Digital Innovator Award, showcasing its impact in automating cloud operations and enhancing SRE efficiency.

Anurag Gupta's CTO Summit talk "Why Systems Fail" covers four types of system failures and mitigation strategies, drawing from his AWS experience in analytics and database services.

Discover how Shoreline Op Packs streamline the process of retiring and replacing Kubernetes worker nodes, ensuring seamless updates and preventing outages.

SRE and Backend Engineering have a lot of overlap, and you can swap between roles relatively easily. This post addresses the pros and cons of leaving SRE for Backend work.

Runbooks are tactical guides for specific tasks, aiming for automation. Playbooks are broader, strategizing over processes and integrating runbooks for efficiency in operations, reducing error and toil.

Automating runbooks streamlines operations, shifting from manual to machine-executed tasks for efficiency in complex environments like Kubernetes. Shoreline's solution, based on real-world experiences, enhances maintenance and incident handling.

Automation and streamlining in operations are promoted as universal solutions, but declarative infrastructure and programmatic deployments have limits.