

Companies have enormous volumes of observability data. Processing it centrally requires money, patience, care, and extra security. In contrast, edge operations—processing, analyzing, then acting on observability data entirely within your own environment—offers a cheaper, faster, fault tolerant, and more secure alternative.
Ops teams need to know what’s broken and why it’s broken to fix an issue. That’s where the true value of observability comes in. But as an environment scales, observability itself becomes a challenge. Slack recently published a detailed paper on the challenges of metrics, events, logs, and traces (MELT) data at scale. The key hurdles referenced:
- High operational complexity: As you scale out, more and more infrastructure is required to handle more and more data. In my own experience, the MELT data from services running can quickly exceed the data from the services themselves.
- Low query latency maintenance: Observability systems need to be low latency for operators to use them to diagnose and fix issues during a live event. As data grows, this becomes more difficult.
- Cost of doing business: MELT requires terabytes of data to go over the network and then terabytes of long term storage. It can get expensive quickly. In addition, these costs make it painful to remove observability tooling or change providers.
Centralized Operations: Easy to Manage, but Expensive, Slow, Fragile, and Vulnerable
There’s a vibrant market for observability services trying to address the challenge of high operational complexity. Most of these services are built using a centralized model (diagram 1).
A centralized model addresses high operational complexity head-on with a central endpoint that collects all data and a central administrative mechanism for creating queries, dashboards, and configuring alerting.
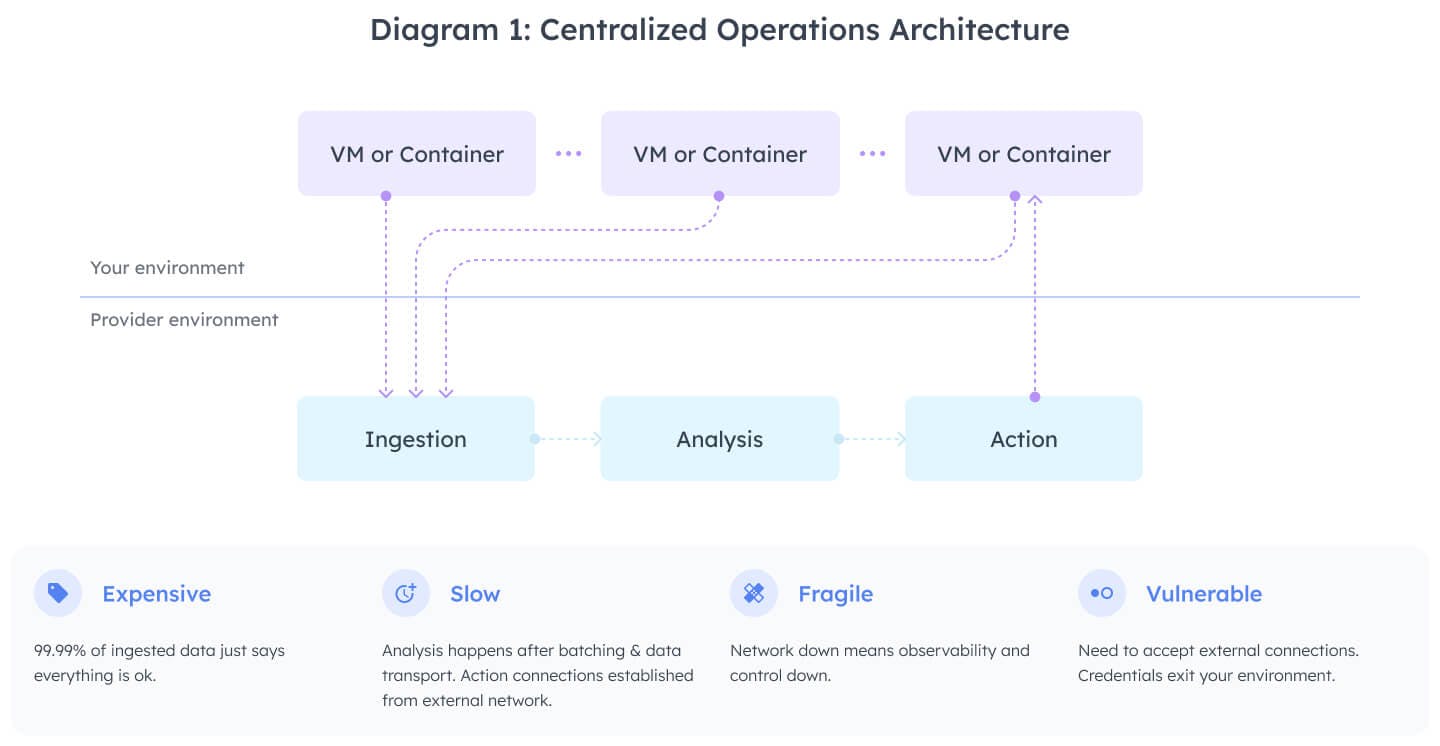
While the centralized model makes querying across hosts straightforward, it exacerbates two main issues: cost and high latency.
In particular, all of the MELT data needs to flow outside of a company’s infrastructure and into the provider’s systems. Moving data off-box may seem like a pragmatic solution but it increases latency which, in turn, drives up MTTD and MTTR. Assessing data against monitors/alarms can take minutes of lag time — which is not compatible with a 4 or 5 nine SLAs.
Since the data is processed only after it is shipped, it needs to be moved to another system, driving up costs - even though the vast majority contains little information, merely saying everything continues to be fine. Log after log will show the request is a 200; data point after data point will say the latency is meeting SLAs. All of this data movement leads to high cloud network transport costs—large services can push terabytes, or even petabytes, of data per day. Additionally, all of this data creates immense storage cost even though the vast majority of observability data will never even be read.
Not only is the centralized model expensive and slow, it’s also fragile and vulnerable. If the network goes down, the entire system stops. We see this often in cloud systems—especially when you need the system to be up most. Further, if you want to go beyond observability, and get into automatic remediation or just accelerated debugging, you have to store credentials in these centralized systems which makes them an attack target. You also need to open your network for access, which leads to increased vulnerability.
Edge Operations: Cheap, Fast, Fault Tolerant, and Secure
Edge operations (illustrated in diagram 2) can help companies address cost, latency and operational complexity better than centralized operations. But taking this approach requires solving key engineering challenges including lightweight agents, smart control planes, and dynamic rules engines—all within a cross-platform environment that simultaneously keeps observability and remediation stack running in your environment.
In this model, there’s an agent running on each VM, but it’s different from the collector agents some providers use to aggregate metrics before sending them to a centralized system. The edge operations agent does much more than simply collect data. It also analyzes data while running your monitors. And when a monitor is triggered, runbook automation can take over to kick off diagnostic commands and remediations—all within a company’s own environment.
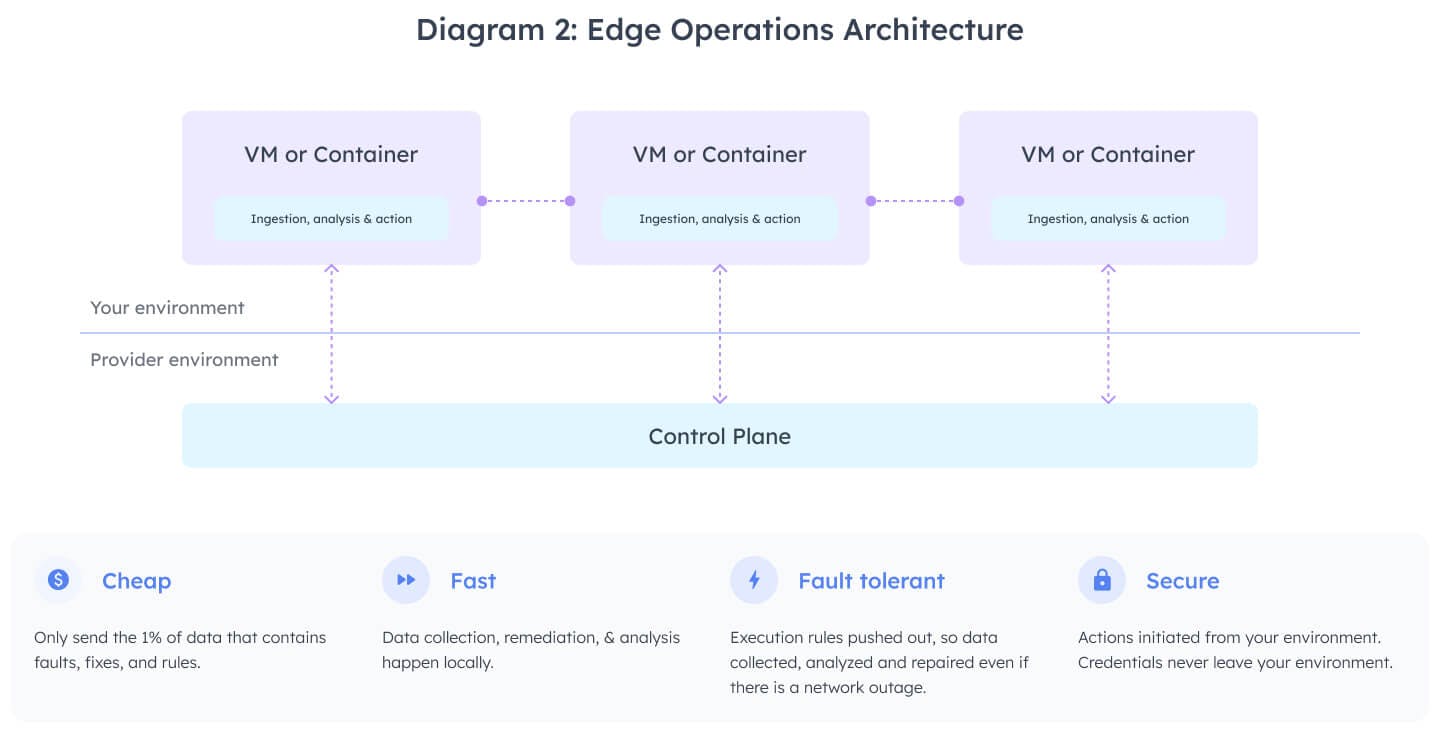
By processing MELT data at the edge, the vast majority (over 99.99%) can be filtered out, leaving behind very little data for centralized long term storage. This dramatically reduces network transport and storage costs. This is possible because most data just says everything is fine and your systems are continuing to run well.
By processing data on-box, companies don’t incur the network latency and processing overhead of shipping data somewhere else. Instead, it can be processed within milliseconds right at the location of generation. This means ops teams can detect earlier and kick off fixes earlier, reducing MTTD and MTTR.
In the event of a network outage, the system continues to work because it is inherently fault-tolerant. The agents continue ingesting data, spool it for sending later, and keep checking for monitors in alarm. If there is a partial failure, you can continue to observe all resources still functioning and pinpoint the impacted resources.
The edge operations model also has security advantages. There are no credentials that leave your environment and no inbound network access needed. Rather than store credentials, credentials are assigned to the agents using standard Kubernetes service account and cloud provider role based delegation, just like any other software you deploy. Instead of opening ports, agents connect to the backend and hold open connections to permit bi-directional communication without opening to any traffic initiated from the outside.
But, to make the edge operations model possible, there are substantial engineering challenges:
- You need a lightweight agent to minimize the on-box CPU and memory used while maximizing the volume of MELT data that can be processed.
- You need a system that can push down computation to the agents and then run these processes efficiently. Since data is being stored locally, you will need a compression mechanism to minimize data on disk.
- You need a control plane for easy code management that is intelligent enough to push down the data processing to the agents. In addition, you’ll need an intelligent query mechanism that can compute aggregates in a distributed manner.
- You need a dynamic rules engine because the agent can’t be redeployed for every change in observability, monitor rules, or actions. Instead, you need a programmable system that makes the process transparent to the end user.
- You need a system that runs cross-environment, cross-cloud, and cross-operating system. Since the agent is everywhere, it needs to run in every environment. Since it does the entire operations stack, the entire functionality needs to be cross-platform.
- You need a system that can integrate with existing observability tools and extend their functionality to enable incremental adoption and value add without rework.
In practice, not every component will run at the edge. For example, dashboarding may be served centrally. To accelerate the dashboard’s queries, there may be centralized caches. To bridge the gap in ease of management between the centralized and edge models, there will be a centralized control plane that delivers configuration to the agents. Overall, real world observability and automation systems will blend both models to optimally serve the needs of ops teams.
Schedule a demo to see how edge operations can benefit your business
+++
Endnote:
Agents of Change
Historically, there’s been widespread disdain for agent-based architectures stemming from three primary factors. First, operators dislike incurring increased cost due to excess usage of system resources by heavy agents. Second, doing the work to guarantee agents were installed to run on each vm introduces management complexity. Third, there’s an inherent need for increased security review scrutiny when software runs locally.
But new cloud native systems are adopting agent-based architectures because the historical challenges can be solved through engineering. Effort can be expended to leverage low-level, compiled languages in developing agents. This allows agents to process tens of thousands of metrics per second, hundreds of monitors, and take remediating action—all for fractions of a modern cpu and less than 200MB of RAM. Furthermore, modern tensor processing frameworks have been developed enabling low cost computation over high volume, dense data.
For example, Helios, the observability system built by Microsoft to observe and manage Azure, leverages a hierarchical architecture where edge based agents initially ingest and process data. Their edge-based agents can leverage the “computation slack” present on their fleet of machines to reduce waste. According to Microsoft engineers, the architecture “yields many additional advantages, e.g., reducing network, computation, and storage requirements.”
Another example is Kubernetes itself. The project has radically simplified deploying and updating agents in the datacenter with the DaemonSet resource—a single change to yaml can now apply changes to the agent across the cluster. In practice, Kubernetes runs a kubelet agent on each node that it administers. The kubelet is responsible for low latency administration of all the containers running locally along with periodically syncing state with the control plane.