

This is our second post in a series to demystify the metrics engine that underpins Shoreline’s real time data. Each of these posts will be a deep dive into one aspect of the engine and how it benefits SREs/DevOps/Sysadmin while they're on call. We’ll showcase our most interesting applications in machine learning, compression, compilers, and distributed systems. Check out the first post in our series: Shoreline Accelerates Ops with JAX & XLA
As operators, we need to know when our systems are broken - any delay in alarming increases mean time to detection and reduces availability. Longer delays mean higher chances of broken SLAs and the resultant correction-of-error and root cause analysis meetings.
To address this, Shoreline has developed a real time alarm mechanism: Shoreline executes 1,000s of alarms on box, with 1 second of delay, so you’ll know immediately when systems are down. Shoreline’s incident automation plugs into real time alarms, allowing mitigation to automatically begin within 1 second of the alarm firing. Shoreline can detect and repair issues before other monitoring systems have even noticed something is going on.
To do this, we extended our metric query compiler, detailed in the first blog post in this series, so that we can export compiled alarms from our backend to execute natively on the agent. Alarms execute as highly optimized machine code. We leveraged Google’s IREE project: a tool chain that allows for representing tensor transformation in a unified way and an export mechanism so computations can be easily sent to other computers.
The Control Loop

Shoreline runs as an agent on every computer that it administers. On Kubernetes, this is achieved with a DaemonSet resource and on virtual machines, such as ec2, this is done through installation of a package (apt or yum).
This local agent runs a control loop: Shoreline continuously monitors the node and its software, looks for issues, and kicks off mitigating actions to resolve the problems as quickly as possible. To configure this loop, users create alarms: metric queries and linux commands that detect bad patterns and states. For example, alarm when cpu utilization exceeds 90% for the last five minutes or alarm when a log file contains a certain error.
To minimize latency, this control loop runs locally. We don’t ship data off to another server and then check for errors. Instead, we do it in real time, right as the data is flowing in on the same machine. This makes the detection resilient to network errors: our agent continues to be able to govern the underlying system even if it loses connection to Shoreline’s backend. But, this also means that we need low memory and cpu utilization to make sure that our agent is using customer resources as efficiently as possible.
Today, we’ll focus on alarms built out of metric queries. We already detailed in our last post in this series how we can vastly accelerate computing metric queries by compiling them using JAX & XLA. We have now extended this one step further: we are able to compile the metric queries within our alarms on Shoreline’s backend and then ship these to the agent for local execution. This allows the agent to check 1,000s of alarms each second, minimizing time to detect errors. Furthermore, because the compilation yields optimized assembly code, this radically reduces memory and cpu utilization compared to competing systems.
Exporting Models With IREE
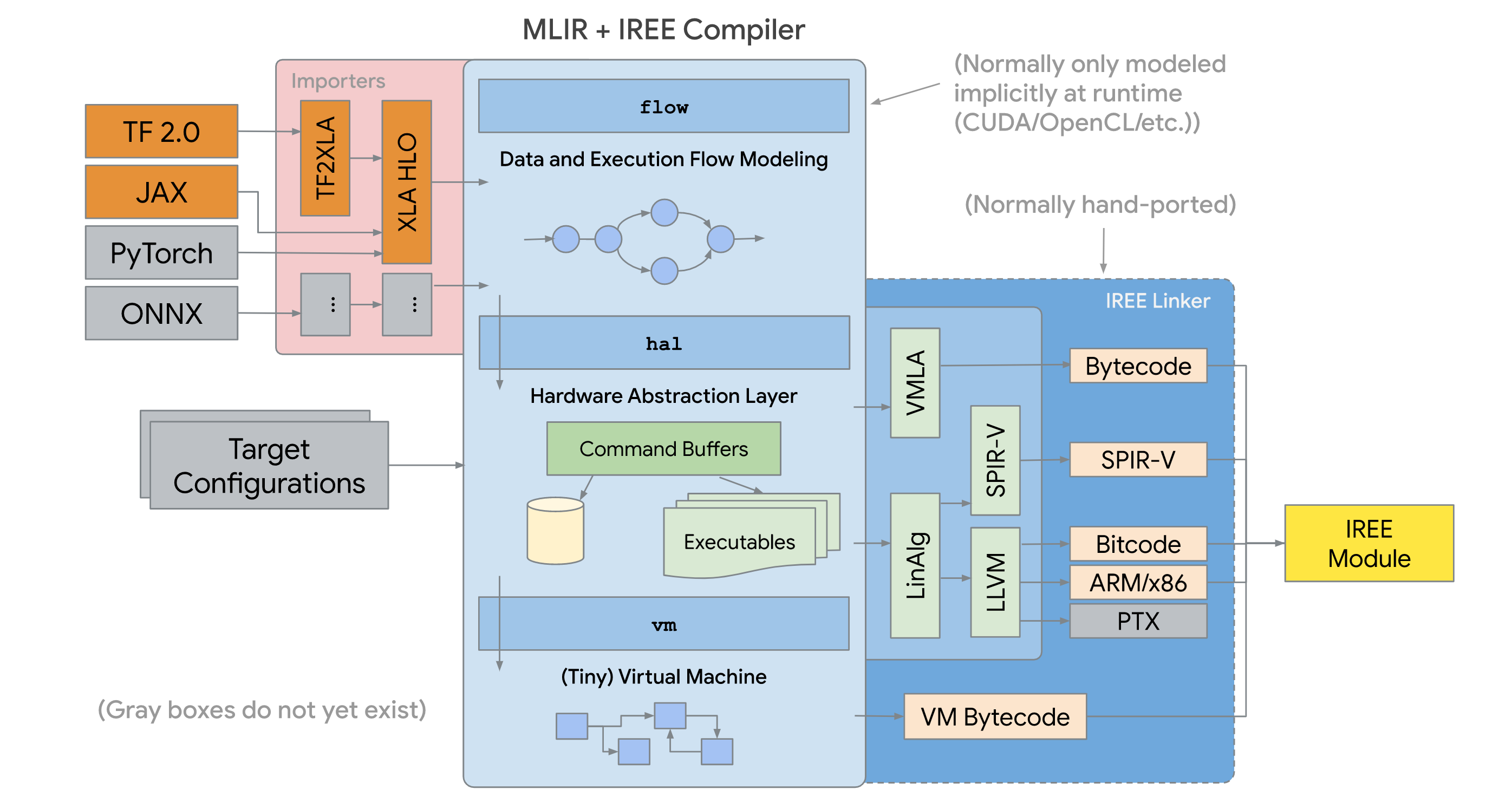
To export our compiled alarms, we leverage Intermediate Representation Execution Environment (IREE), a project from Google. IREE is a fast, light ML framework focused on representing tensor operations in an intermediate format and then exporting them using a variety of plugins. For example, IREE can be used to take a model built using TensorFlow and export it for execution on an Android based mobile device.
We use IREE to export our compiled alarms, built using JAX, in a format that can execute within Shoreline agents. JAX outputs its computations in High Level Operations (HLO) and IREE uses ahead of time (AOT) compilation to convert the computation into a compiled format.
At a high level, we invoke our existing compiler that builds a metric query using JAX. We then use IREE to export the computation to file. Then Shoreline ships the compiled alarm file to the agents. Finally, the agents load and begin executing the compiled alarm. The heavy lifting of compilation happens on our backend while lightweight execution of the alarm happens on the agent.
Since a major use case for IREE is export for mobile devices, its formats support very low memory usage. Importing the IREE and running complex JAX models on our agents takes as little as 3MB of RAM. The exported models are often less to 50KB of data each.
How do we “compile” an alarm?
Let’s breakdown how compilation actually works:
- Metric queries are mapped from our op language to specific NumPy functions
- Metric queries are then mapped to specific JAX steps
- JAX HLOs for the metric queries are now sent to our TensorTransformBuilder to be optimized by IREE
- IREE generates small binary files that can be ran against an alarm's input and output the state of the alarm (normal/firing/resolved)
- The Shoreline backend then ships these files to the agents
- Agents read these compiled alarms and configure their local control loops to execute them for matching resources
One enhancement we did was to ensure that we support running metric queries against a varying number of time series since resources are dynamic. Upon AOT compilation, IREE needs specific data shapes which is not feasible in a real life scenario. For example, different instance types have different numbers of cpus and different virtual machines may be running different pods. Our overlay for JAX/IREE compiles models for generic shapes – for 1 time series, 2 time series, 4 time series etc… We were inspired by C++ STL's exponential way of allocating memory for STL vectors when they need to be extended. At runtime, we choose the model to run based on the best match between the actual data shape and the generic data shapes that models were built for.
Even if we generate multiple models in this way, we make sure to only load those we actually need in the Agent's memory – this keeps resource usage low and also provides a fallback if the data gets bigger – we'll load a beefier model and disregard the previous one, without any recompilation.
Cross Compile: Supporting ARM and x86

Many infrastructure groups are now leveraging ARM based servers in addition to classic x86 machines. The expansion of ARM in the data center has only intensified with AWS’s release of Graviton instance types- it’s now easier than ever to spin up ARM based servers. But this poses a challenge for compiled alarms: now we need to compile for multiple CPU architectures.
Luckily, the compilation process is flexible and it allows alarms to be compiled for multiple cpu architectures. We worked over the last month to set up a cross compiling tool chain: our backend generates compiled alarms for ARM and x86 servers. No matter which CPU architecture you choose, Shoreline will transparently ship down the appropriately compiled alarms so you can benefit from real time detection of errors.
We recently ported our agent container entirely to ARM, so you can administer clusters of ARM based servers and even mixed mode clusters (ARM and x86) seamlessly. We will detail this in another blog post.
Looking to the Future
We're heading towards a fully-compiled flow for our alarm computation. We don’t yet compile the orchestration logic of our metric subsystem. This is changing - in our next post, we’ll detail how we efficiently bridge from go to IREE and ported our entire query engine to compiled code. We’ll describe how this reduces our memory and cpu usage even further - you can now run Shoreline on even the smallest instance types and benefit from incident automation. Looking further out, we’ll detail how we leverage our distributed architecture and tensor mechanisms to accelerate machine learning for operations.
As always, if any of this work interests you, we are hiring! Please reach out to charles@shoreline.io